PostgreSQL
PostgreSQL
PostgreSQL은 오픈소스 관계형 데이터베이스로 대용량 Transaction 처리, GIS에 유용한 특징을 가지고 있습니다.
🔎 관계형데이터베이스는 정규화된 테이블로 이루어져 있습니다.
(column(attribute) row(tuple))
환경설정
• 설치하기
PostgreSQL
공식 홈페이지에서 PostgreSQL을 설치할 수 있습니다. 설치 후, 아래 명령어를 터미널에 입력하여 PostgreSQL CLI를 사용할 수 있도록 설정합니다.
sudo mkdir -p /etc/paths.d &&
echo /Applications/Postgres.app/Contents/Versions/latest/bin | sudo tee /etc/paths.d/postgresapp
psql
psql은 postgres cli입니다.
pgAdmin
PostgreSQL의 GUI 환경으로, 공식 홈페이지에서 pgAdmin을 설치할 수 있습니다.
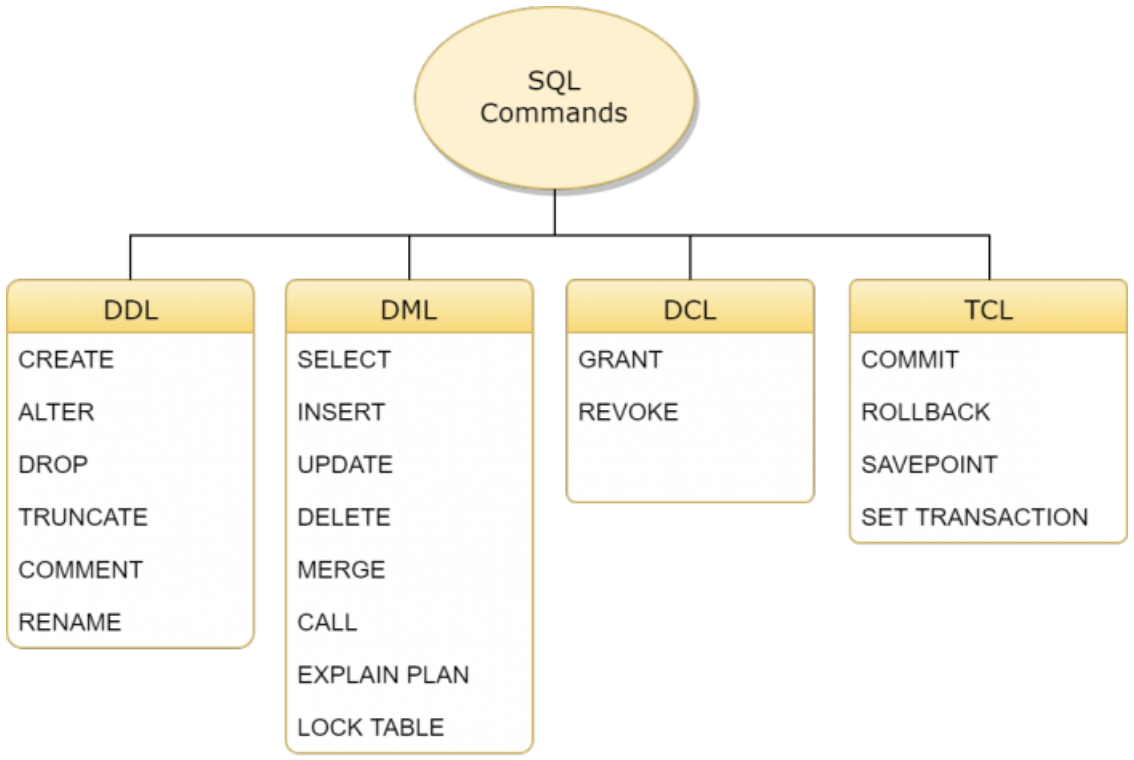
SQL문
postgreSQL cli인 psql 또는 sql 편집기를 통해 database를 다룰 수 있습니다.
• Database 만들기
CREATE DATABASE [DB이름];을 통해 database를 만들 수 있습니다.
• Database 지우기
DROP DATABASE [DB이름];을 통해 database를 지울 수 있습니다.
• Database 연결하기
psql [Option]... [DBNAME [USERNAME]]를 통해 database에 연결 할 수 있으며, 아래는 예시 입력입니다.
psql -h localhost -p 5432 -U minho [DB이름]
🔎 Option은 psql --help를 터미널에 입력하여 볼 수 있습니다.
• Table 만들기
table은 아래와 같이 CREATE TABLE [table 이름] ([column 이름] [Data Type])으로 만들며, \d로 database에 있는 table들을 또는 \d [table 이름]으로 table의 column들을 볼 수 있습니다.
CREATE TABLE table_name (
column datatype constraint
...
);
• Table 지우기
DROP TABLE [table 이름]으로 table을 지울 수 있습니다.
DROP TABLE table;
• Table 수정하기
https://www.postgresql.org/docs/10/sql-altertable.html
- column 추가하기
ALTER TABLE [table 이름] ADD [column 이름] [Data Type]으로 table에 column을 추가할 수 있습니다.
- table 이름 바꾸기
ALTER TABLE [현재 table 이름] RENAME TO [새로운 table 이름]으로 table의 column 이름을 바꿀 수 있습니다.
- column 이름 바꾸기
ALTER TABLE [table 이름] RENAME [현재 column 이름] COLUMN TO [새로운 column 이름]으로 table의 column 이름을 바꿀 수 있습니다.
- column 지우기
ALTER TABLE [table 이름] DROP COLUMN [column 이름]으로 table의 column을 지울 수 있습니다.
- column 자료형 바꾸기
ALTER TABLE [table 이름] ALTER COLUMN [column 이름] TYPE [Data Type]으로 column의 Data Type을 바꿀 수 있습니다.
- constraint 수정하기
ALTER TABLE [table 이름] ADD CONTRAINT...으로 column의 constraint를 바꿀 수 있습니다.
• Row 수정하기
아래와 같이 UPDATE을 통해 table의 해당 row, coulmn을 업데이트 할 수 있습니다.
UPDATE [table 이름] SET [column 이름] = [새로운 값] WHERE [조건]
WHERE이 없다면 모든 row에 대해 업데이트를 수행합니다.
UPDATE [table 이름] SET [column 이름] = [새로운 값]
RETURNING을 통해 업데이트 된 행을 볼 수 있습니다.
UPDATE [table 이름] SET [column 이름] = [새로운 값] WHERE [조건] RETURNING *
🔎 UPSERT
UPSERT란 해당 조건에 맞는 row가 있으면 update하고, 없다면 insert하는 것을 의미합니다.
INSERT INTO [table 이름] ([column 이름]) VALUES ([column 값]) ON CONFLICT [충돌 조건] 이며, 충돌 조건 다음에 오는 syntax는 아래 두가지가 있습니다.
DO UPDATE SET [column 이름] = [새로운 값] WHERE [조건],
DO NOTHING
• Row 삽입하기
아래와 같이 INSERT를 통해 해당 table에 row(record)를 삽입할 수 있습니다.
INSERT INTO [talbe 이름] ([column 이름]) VALUES ([column 값]), ...
RETURNING을 통해 삽입된 행을 볼 수 있습니다.
INSERT INTO [talbe 이름] ([column 이름]) VALUES ([column 값]), ... RETURNING *
• Row 삭제하기
아래와 같이 DELETE을 통해 table의 해당 row를 삭제 할 수 있습니다.
DELETE FROM [table 이름] WHERE [조건]
WHERE이 없다면 모든 행을 지웁니다.
DELETE FROM [table 이름]
• Row 조회하기
아래와 같이 SELECT을 통해 table을 조회할 수 있습니다.
SELECT [column 이름] FROM [table 이름]
SELECT column, ... FROM table;
또한, DISTINCT를 통해 중복값을 없애고 조회할 수 있습니다.
SELECT DISTINCT[column 이름] FROM [table 이름]
SELECT DISTINCT column, ... FROM table;
🔎 ON 키워드를 통해 중복된 특정 column을 정의할 수 있습니다.
SELECT는 WHERE, LIMIT 등을 통해 여러가지 형태로 table을 조회할 수 있습니다.
- WHERE
WHERE은 여러 조건 AND/OR, IN, NOT IN, BETWEEN, LIKE, NOT LIKE, IS NULL, IS NOT NULL 조합을 통해 조건에 맞는 record만 조회할 수 있습니다.
SELECT [column 이름] FROM [table 이름] WHERE [조건]
SELECT column, ... FROM table
WHERE column = ... AND ... OR ... IN ... NOT IN ... BETWEEN ... NOT BETWEEN ... LIKE ... NOT LIKE ... IS NULL ... IS NOT NULL ...;
WHERE column = a AND column = b;
WHERE column = a OR column = b;
WHERE column IN (a, b);
WHERE column NOT IN (a, b);
WHERE column BETWEEN a AND b;
WHERE column NOT BETWEEN a AND b;
WHERE column LIKE a%;
WHERE column NOT LIKE a_;
WHERE column IS NULL;
WHERE column IS NOT NULL;
- LIMIT
LIMIT를 통해 조회하는 row 수를 제한합니다. OFFSET과 같이 사용될 수 있습니다.
SELECT [column 이름] FROM [table 이름] LIMIT [가져올 record 수]
SELECT [column 이름] FROM [table 이름] OFFSET [시작행] LIMIT [가져올 record 수]
SELECT column, ... FROM table LIMIT number;
SELECT column, ... FROM table OFFSET row LIMIT number;
🔎 단지, SELECT로 조회한 row에서 보여주는 수를 제한합니다.
- FETCH
FETCH를 통해 조회하는 row 수를 제한합니다. OFFSET, FETCH와 같이 사용될 수 있습니다.
SELECT [column 이름] FROM [table 이름] FETCH FIRST [가져올 record 수] ROW ONLY
SELECT [column 이름] FROM [table 이름] OFFSET [시작행] FETCH FIRST [가져올 record 수] ROW ONLY
SELECT column, ... FROM table FETCH FIRST number ROW ONLY;
SELECT column, ... FROM table OFFSET row FETCH FIRST number ROW ONLY;
🔎 단지, SELECT로 조회한 row에서 보여주는 수를 제한합니다.
- GROUP BY
GROUP BY에서 COUNT, SUM 등의 aggreation 함수를 통해 group의 정보(통계)를 알 수 있습니다. HAVING과 함께 사용될 수 있습니다.
SELECT [column 이름] 통계식 FROM [table 이름] GROUP BY [기준 column]
SELECT column, ... FROM table GROUP BY column;
• Table 정렬하기
아래와 같이 ORDER BY를 통해 table을 정렬할 수 있습니다.
SELECT [column 이름] FROM [table 이름] ORDER BY [기준 column] [오름차순/내림차순]
SELECT column, ... from table ORDER BY column, ... ASC;
• Constraint 만들기
constraint(https://www.tutorialspoint.com/postgresql/postgresql_constraints.htm)는 table 및 column에 제한을 걸어, 테이블의 신뢰성을 높일 수 있습니다.
- NOT NULL
해당 column은 null을 허용하지 않습니다. (값을 가져야합니다.)
CREATE TABLE [table 이름] (
[column 이름] [data type] NOT NULL
);
ALTER TABLE [table 이름] ALTER COLUMN [column 이름] SET NOT NULL;
- UNIQUE
해당 column에 고유한 값이 저장되며, 이를 위해 데이터를 저장할때마다 검사합니다.
CREATE TABLE [table 이름] (
[column 이름] [data type] UNIQUE
);
ALTER TABLE [table 이름] ADD [constraint 이름] CONSTRAINT UNIQUE ([column 이름]);
- DEFAULT
값이 입력되지 않으면, default 값을 저장합니다.
CREATE TABLE [table 이름] (
[column 이름] [data type] DEFAULT [default value]
);
ALTER TABLE [table 이름] ALTER COLUMN [column 이름] SET DEFAULT [dafault value];
- PRIMARY KEY
table에서 row를 식별할 수 있는 고유 key입니다. primary key는 table에 하나만 존재해야 하며, 여러개의 column으로 만들어진 primary key를 composite key로 부릅니다. primary key는 UNIQUE NOT NULL과 같습니다.
CREATE TABLE [table 이름] (
[column 이름] [data type] PRIMARY KEY
);
ALTER TABLE [table 이름] ADD [constraint 이름] CONSTRAINT PRIMARY KEY ([column 이름]);
- FOREIGN KEY
foreign key는 다른 table의 primary key를 참조하는 column입니다. foreign key로 두 테이블은 연결되어 있기에 foreign table에 없는 값을 저장하면 오류가 발생합니다.
CREATE TABLE [table a 이름] (
[column a 이름] [data type]
FOREIGN KEY [column a 이름] REFERENCES [table b 이름] [column b 이름]
);
CREATE TABLE [table b 이름] (
[column b 이름] [data type] PRIMARY KEY
);
ALTER TABLE [table a 이름] ADD [constraint 이름] FOREIGN KEY ([column a 이름]) REFERENCE [table b 이름]([column b 이름]);]
[ON DELETE CAST | RESTRICT]
🔎 table a는 column a(foreign key)를 통해 table b(foreign table)를 참조합니다.
- CHECK 저장될 값이 어떠한 조건을 만족하는지 검사합니다.
• Constraint 지우기
아래 sql을 통해 constraint를 지울 수 있습니다.
ALTER TABLE [table 이름] DROP CONSTRAINT [constraint 이름]
• Table 연결하기
아래와 같이 Join을 통해 table을 연결할 수 있습니다. 조건에 따라 join을 하면 기준 테이블 옆에 join되는 테이블이 붙어 새로운 테이블이 만들어 집니다.
- (Inner) Join
inner join은 on 조건에 맞는 table a와 table b의 행들을 연결하여 새로운 테이블을 만듭니다.
SELECT [column 이름] FROM [table a 이름] JOIN [table b 이름] ON [table a's common column] = [table b's common column]
SELECT [column 이름] FROM [table a 이름] JOIN [table b 이름] USING [tables' common column]
SELECT * FROM table_a JOIN table_b ON table_a's common_column = table_b's common_column
SELECT * FROM table_a JOIN table_b USING common_column
🔎 table b의 common_column은 foreign key로 primary key가 되어야 합니다.
- Left(Outer) Join
left join은 왼쪽 테이블을 기준으로, on 조건에 맞는 table b의 행들을 연결하여 새로운 테이블을 만듭니다.
SELECT [column 이름] FROM [table a 이름] LEFT JOIN [table b 이름] ON [table a's common column] = [table b's common column]
SELECT * FROM table_a LEFT JOIN table_b ON table_a's common_column = table_b's common_column
- Right(Outer) Join
right join은 오른쪽 테이블을 기준으로, on 조건에 맞는 table b의 행들을 연결하여 새로운 테이블을 만듭니다.
SELECT [column 이름] FROM [table a 이름] RIGHT JOIN [table b 이름] ON [table a's common column] = [table b's common column]
SELECT * FROM table_a RIGHT JOIN table_b ON table_a's common_column = table_b's common_column
- Full(Outer) Join
full join은 왼쪽/오른쪽 테이블을 기준으로, on 조건에 맞는 table b의 행들을 연결하여 새로운 테이블을 만듭니다.
SELECT [column 이름] FROM [table a 이름] FULL JOIN [table b 이름] ON [table a's common column] = [table b's common column]
SELECT * FROM table_a FULL JOIN table_b ON table_a's common_column = table_b's common_column
- Cross Join
cross join은 왼쪽/오른쪽 테이블을 서로 교차한 행들을 연결하여 새로운 테이블을 만듭니다. 따라서, 왼쪽 테이블이 n행이고 오른쪽 테이블이 m행이라면 n * m행의 테이블이 만들어지게 됩니다.
SELECT [column 이름] FROM [table a 이름] CROSS JOIN [table b 이름]
SELECT * FROM table_a CROSS JOIN table_b
- Self Join
- Nautral Join
- COALESCE
• Subquery
아래와 같이 다른 쿼리문 안에 감싸져 있는 쿼리를 서브쿼리라 합니다. 서브쿼리는 SELECT, INSERT, UPDATE, DELETE와 함께 사용됩니다. 서브쿼리는 단일행, 다중행, 연관 서브쿼리, 인라인뷰가 있습니다.
- Single Row 서브쿼리
서브쿼리의 결과는 단일행, 단일열이며 비교연산자와 함께 사용됩니다.
SELECT * FROM [table a 이름] WHERE [비교 조건] (SELECT [단일 column] FROM [table b 이름])
- Multiple Row 서브쿼리
서브쿼리의 결과는 다중행, 단일열이며 in, exists, not in, any, some, all 연산자와 함께 사용됩니다.
SELECT * FROM [table a 이름] WHERE [in, exists, not in, any, some, all] (SELECT [단일 column] FROM [table b 이름])
🔎서브쿼리는 BETWEEN과 함께 사용될 수 없습니다. (서브쿼리 안에서는 BEWEEN을 사용할 수 있습니다.)
- Inline View 서브쿼리
서브쿼리의 결과는 테이블로, 테이블에서 조회할 수 있습니다.
SELECT * FROM (SELECT * FROM [table 이름]) as t
- Correlated 서브쿼리
서브쿼리가 메인 테이블을 참조합니다.
SELECT *, (SELECT * FROM [table b 이름] WHERE a.column ...) FROM [table a 이름] as a
• Transaction
Database를 수정 중 문제가 발생하면, 작업이 완전히 끝나지 않 Database는 중간의 데이터를 저장하고 있습니다. 또한 database에 다른 작업이 실행 중인데, 또 다른 작업이 끼어든다면 database가 꼬이게 됩니다. Transaction은 여러개의 Database 작업을 하나로 묶어, Database를 요구대로 수정하거나 아예 바꾸지 않게 해주며, ACID(Atomicity, Consistency, Isolation, Durability) 특성을 가지고 있습니다.
- Atomicity: Transaction은 하나의 작업으로 여겨져야 합니다.
- Consistency: Transaction의 결과는 일관성이 있어야합니다.
- Isolation: Transaction 작업 시, 또다른 Transaction으로부터 고립되어야 합니다.
- Durability: 반영된 transaction 결과는 database에 영구히 저장됩니다.
이러한 transaction은 SQL문은 아래와 같습니다.
- BEGIN: transation의 시작점입니다.
- COMMIT: transaction의 끝점입니다.
- ROLLBACK: transaction 작업 중 오류가 발생하면, 제일 가까운 database로 원복시킵니다.
- SAVEPOINT: transaction 작업 중 오류가 발생하면, 원복될 지점을 정의합니다.
🔎 transaction의 작업 단위는 BEGIN [작업...] COMMIT으로 정의합니다. 만일 COMMIT이 없다면 transaction이 끝나지 않기에 database에 변화는 없습니다.
ACID(Atomicity, Consistency, Isolation, Durability)
• postgreSQL 연산자
postgreSQL 연산자는 산술, 비교, 논리, 비트 연산자가 있습니다.
• postgreSQL 자료형
https://www.tutorialspoint.com/postgresql/postgresql_data_types.htm - boolean: TRUE, FALSE, NULL (TRUE, ‘true’, ‘false’, ‘t’, ‘f’, ‘y’, ‘n’, ‘yes’, ‘1’, ‘0’)
- string: CHARACTER(n)/CHAR(n) 고정된 길이, CHARACTER VARYING(n)/VARCHAR(n) 변할수 있는 길이 (+제한 길이), TEXT/VARCHAR 길이제한 없음
- number:
| smallint | 2byte | -32768 ~ 32767 |
| integer | 4byte | -2147483648 ~ 2147483647 |
| bigint | 8byte | 9223372036854775808 ~ 9223372036854775807 |
| smallserial | 2byte | 1 ~ 32767 |
| serial | 4byte | 1 ~ 2147483647 |
| bigserial | 8byte | 1 ~ 9223372036854775807 |
- decimal:
| numeric(n, m), decimal | variable | 소수점 앞, 소수점 뒤 |
| real | 4byte | 유효 소수점 6자리 |
| double precision | 8byte | 유효 소수점 15자리 |
- date / time:
| date | 날짜 | YYYY-MM-DD |
| time | 시간 | HH:MM, HH:MM:SS, HHMMSS, MM:SS.pppppp, HH:MM:SS.pppppp, HHMMSS.pppppp |
| timestamp | 날짜 + 시간 | |
| timestamptz | 날짜 + 시간 + 타임스탬프 | 유효 소수점 15자리 |
timestamp는 현재 utc 시간을 보여줌 2021-08-01 01:00 timestamp는 해당 timezone의 현재 시간을 보여줌 2021-08-01 09:00
- date / time:
https://medium.com/building-the-system/how-to-store-dates-and-times-in-postgresql-269bda8d6403
*CURRENT_DATE
• postgreSQL 날짜 다루기
select
date('2020-3-1') - date('2020-2-28')
• sequence
- Sequence 만들기
CREATE SEQUENCE IF NOT EXISTS [sequence 이름]
- Sequence 실행 및 조회
nextval을 통해 다음 값을, curval을 통해 현재 값을 반환받을 수 있습니다.
SELECT nextval([sequence 이름])
SELECT curval([sequence 이름])
- Sequence 설정
setval로 sequence의 값을 설정할 수 있습니다.
SELECT setval([sequence 이름], [설정할 값], [skip 여부])
START WITH로 sequence의 초기값을 설정할 수 있습니다.
CREATE SEQUENCE IF NOT EXISTS [sequence 이름] START WITH [시작 값]
RESTART WITH로 sequence 값을 다시 새로운 값부터 시작시킬 수 있습니다.
ALTER SEQUENCE [sequence 이름] RESTART WITH [시작 값]
RENAME TO로 sequence 이름을 바꿀 수 있습니다.
ALTER SEQUENCE [sequence 이름] RENAME TO [시작 값]
INCREMENT, MINVALUE, MAXVALUE, ‘CYCLE’로 sequence의 증분, 최소, 최대값, 반복여부를 설정할 수 있습니다.
CREATE SEQUENCE IF NOT EXISTS [sequence 이름]
INCREMENT [증분]
MINVALUE [최소값]
MAXVALUE [최대값]
START [시작 값]
CYCLE
AS로 sequence의 자료형을 설정할 수 있습니다.
CREATE SEQUENCE IF NOT EXISTS [sequence 이름] AS [자료형]
- Sequence 지우기
DROP SEQUENCE [sequence 이름]
- Sequence 반영하기
CREATE SEQUENCE IF NOT EXISTS [sequence 이름] OWNED BY [table 이름].[column 이름];
CREATE TABLE [table 이름] (
[column 이름] [자료형] DEFAULT nextval([sequence 이름])
)
CREATE SEQUENCE IF NOT EXISTS [sequence 이름] OWNED BY [table 이름].[column 이름];
ALTER TABLE [table 이름] ALTER COLUMN [column 이름] SET DEFAULT nexval([sequence 이름]);
- identity
[column 이름] [data type] GENERATED (ALWAYS|BY DEFAULT) AS IDENTITY
🔎 by default일 경우, override가 되기에 unique가 지켜지지 않습니다. serial vs identity
• aggregate function
- count
count를 통해 해당 column의 row 수를 구할 수 있습니다.
SELECT COUNT([column 이름]) FROM [table 이름]
SELECT COUNT(DISTINCT([column 이름])) FROM [table 이름]
- sum
sum를 통해 해당 column의 합계를 구할 수 있습니다.
SELECT SUM([column 이름]) FROM [table 이름]
SELECT SUM(DISTINCT([column 이름])) FROM [table 이름]
- min/max
min, max를 통해 해당 column의 최소/최대값을 구할 수 있습니다.
SELECT MIN([column 이름]) FROM [table 이름]
SELECT MAX([column 이름]) FROM [table 이름]
- greatest/least
greatest, least를 통해 해당 list의 최소/최대값을 구할 수 있습니다.
SELECT GRETEST(같은 자료형, 같은 자료형 ...) FROM [table 이름]
SELECT LEAST(같은 자료형, 같은 자료형 ...) FROM [table 이름]
- avg
avg를 통해 해당 column의 평균을 구할 수 있습니다.
SELECT AVG([column 이름]) FROM [table 이름]
SELECT AVG(DISTINCT([column 이름])) FROM [table 이름]
🔎 avg는 null은 무시합니다.
- 산술연산자
+ - / * %를 통해 해당 column을 aggreate할 수 있습니다.
SELECT [column 이름] [+ - / * %] [column 이름] ... FROM [table 이름]
• group
- GROUP BY GROUP BY에서 COUNT, SUM 등의 aggreation 함수를 통해 group의 정보(통계)를 알 수 있습니다. HAVING과 함께 사용될 수 있습니다.
SELECT [기준 column 이름] 통계식[column 이름] FROM [table 이름] GROUP BY [기준 column 이름]
FROM WHERE GROUP BY HAVING SELECT DISTINCT ORDER BY LIMIT
• JSON
jsonb는 json의 binary 형식으로 아래와 같이 차이점이 있습니다. |json|jsonb| |-|-|ㅣㅏ ㅂ
- jsonb_build_object
jsonb 객체를 만듭니다.
select jsonb_build_object('name', first_name||' '||last_name, 'contact', jsonb_build_object('email', email, 'phone', phone_number)) from users;
{"name": "Kate Deedes", "contact": {"email": "kdeedes0@wikipedia.org", "phone": "766-876-2982"}}
jsonb_agg
::jsonb (:: type cast)
[JSONB 연산]
- –>
jsonb의 해당 key를 ‘‘의 문자열로 반환합니다.
SELECT book_info->'title'
- –»
jsonb의 해당 key를 문자열로 반환합니다.
SELECT book_info->>'title'
-||
jsonb의 해당 key를 문자열로 반환합니다.
UPDATE SET book_info = book_info || { "title": "physics" } WHERE book_info->> 'title'='title_a'
- row_to_json
table의 모든 행/열을 json으로 바꿉니다. (하나의 열로 변환됩니다)
SELECT row_to_json(book) FROM book
- json_agg
aggregate를 위해 array 형태의 json을 만듭니다. (row_to_json이 배열에 담겨있는 형태입니다.)
SELECT json_agg(b) FROM (SELECT book_info FROM book) as b
Function
postgresql 함수를 정의하여 sql을 실행할 수 있습니다.
• 함수 선언
- sql
CREATE [OR REPLACE] FUNCTION function_name([입력 자료형]) RETURNS [반환 자료형] AS
'
[sql 로직]
'
LANGUAGE SQL
- dollar sign
`대신 $$를 사용할 수 있습니다.
CREATE [OR REPLACE] FUNCTION function_name([입력 자료형]) RETURNS [반환 자료형] AS
$$
[sql 로직]
$$
LANGUAGE SQL
CREATE [OR REPLACE] FUNCTION function_name([입력 자료형]) RETURNS [반환 자료형] AS
${body}$
[sql 로직]
${body}$
LANGUAGE SQL
• 반환값
- void
void(null)를 반환합니다.
CREATE [OR REPLACE] FUNCTION function_name([입력 자료형]) RETURNS void AS
$$
[sql 로직]
$$
LANGUAGE SQL
- 단일 값 반환
자료형에 맞는 단일값을 반환합니다.
CREATE [OR REPLACE] FUNCTION function_name([입력 자료형]) RETURNS [반환 자료형] AS
$$
[sql 로직]
$$
LANGUAGE SQL
- 다중행 반환
자료형에 맞는 단일값을 반환합니다.
CREATE [OR REPLACE] FUNCTION function_name([입력 자료형]) RETURNS SETOF [반환 자료형] AS
$$
[sql 로직]
$$
LANGUAGE SQL
- 테이블 반환
자료형에 맞는 단일값을 반환합니다.
CREATE [OR REPLACE] FUNCTION function_name([입력 자료형]) RETURNS TABLE ([column 이름 반환 자료형]) AS
$$
[sql 로직]
$$
LANGUAGE SQL
• 매개변수
**- **
CREATE [OR REPLACE] FUNCTION function_name([인자 이름] [입력 자료형], [인자 이름] [입력 자료형] ...) RETURNS [반환 자료형] AS
$$
[sql 로직]
...
$1, $2 ...
$$
LANGUAGE SQL
CREATE [OR REPLACE] FUNCTION function_name([인자 이름] [입력 자료형], [인자 이름] [입력 자료형] ...) RETURNS [반환 자료형] AS
$$
[sql 로직]
...
[인자이름], [인자이름] ...
$$
LANGUAGE SQL
반복문
• loop
• for
for [count] in [시작]..[종료] [by [증분]
loop
[...]
end loop;
do
$$
--declare
--i integer;
begin
for i in 1..10
loop
--select id from bookmarks limit 10;
--loop
--select * from bookmarks b
update bookmarks set bookmark_number = 11;
end loop;
end;
$$ language plpgsql;
• for in
do
$$
declare
rec ;
begin
for rec in
select id from bookmarks limit 10
loop
end loop;
end;
$$ language plpgsql;
Optimization
• Index
index란 database engine이 조회를 빠르게 하기 위한 목차같은 또다른 테이블입니다.
인덱스는 row의 컬럼으로 만듭니다.
- Index 만들기
인덱스는 테이블의 column을 넣어 만듭니다. 이때 인덱스를 만들때 column 중복여부에 따라, Index / Unique Index를 정의할 수 있습니다. 일반 index는 create index [index 이름] on [table 이름] [method 이름](column 이름 [index 정렬 기준] [], ...), unique index는 create unique index [index 이름] on [table 이름] (column 이름, ...)으로 만들 수 있습니다.
🔎 모든 column을 넣으면 insert/update/delete 성능이 떨어집니다.
CREATE INDEX index_name ON table_name (column_a, column_b, ...);
CREATE UNIQUE INDEX index_name ON table_name (column_a, column_b, ...);
모든 컬럼이 unique해야함
index 이름 convention idx[table 이름][column 이름] uniue index 이름 convention idxu [table 이름]_[column 이름] 많이 쓰이는 coulmun을 앞에 두어야함 select _ from pg_indexes; select pg_indexes_size(‘users’); select pg_size_pretty(pg_indexes_size(‘users’)); select _ from pg_stat_all_indexes where relname = ‘users’;
- Index 삭제하기
drop index [concurrently] [index 이름] [cascade|restrict]를 통해 index를 지울 수 있습니다.
DROP INDEX index_name;
Execution Stage
sql은 declarive language이기 때문에, sql을 작성하면 sql enigne이 최적화를 하여 database를 다룹니다. 따라서 sql 최적화를 위해 sql engine이 sql을 어떻게 처리하고 실행하는지 이해할 필요가 있습니다. sql engine은 크게 아래의 네 단계를 거쳐 sql을 실행합니다.
1. parser
sql문이 유효한지 해석합니다.
2. rewriter
sql engine이 이해할 수 있도록, original sql로 다시 구문을 작성합니다.
3. optimizer
optimizer는 아래 기준에 따라 database를 다루기 위한 최적의 경로를 찾습니다.
4. executor
optimizer에서 정해진 최적 경로에 따라, database를 다룹니다.
• Explain
- explain
explain 키워드를 통해 쿼리 실행 계획을 볼 수 있습니다. explain 결과에서 노드는 (cost, rows , width) 속성을 가지고 있으며 아래 부터 읽습니다.
🔎 실제로 쿼리를 실행하지는 않습니다.
explain select * from table ...
- explain analyze
explain ananlyze 키워드를 통해 쿼리 실행 결과를 볼 수 있습니다.
explain analyze select * from table ...
explain (analyze) vs explain analyze?
• Optimizer
optimizer는 아래 기준에 따라, 최적의 경로를 선택합니다.
- cost
cost가 제일 적은 경로를 선택합니다.
- thread
thread database를 thread로 나누어 동시에 작업합니다.
- node
nodes database의 작업단계를 나눈 단위입니다.
• Node Type
Node는 stackable입니다. Parent Node Childe Node 1 Childe Node 2 Childe Node2부터 시작하며 ouuput은 childe node1의 Input이 됩니다.
node 종류
gather node parrel seq scan node show max_parallel_workers_per_gather show seq_page_cost show cpu_tupe_cost
select pg_relation_size select pg_size_pretty
- sequential scan
기본적인 node로, table을 첫행부터 끝까지 (scan)읽습니다.
🔎 모든 table을 읽어야 filtering이 가능하기에, where을 작성해도 sequential scan 과정이 들어갑니다.
- index scan
index table에서 조건에 맞는 row들을 찾은 후, 이를 기반으로 해당 table에서 row를 읽어옵니다.
- index only scan
index table에서 조건에 맞는 row를 바로 읽어옵니다.
가져오는 column과 조건이 index의 column으로만 되어 있으면,
- bitmap index scan
- join node join node는 hash join / merge join / nested loop join으로 나뉩니다.
nested loop join inner(left) table을 기준으로 join 조건이 일치하는 outer(right) table의 행을 탐색/순회하며, 이를 inner table 행만큼 반복합니다. (이중 for문과 유사합니다.) 로직이 간단하기에 테이블이 커지면 시간이 오래걸리는 단점이 있습니다. driving(선행) table은 바뀔 수 있으며, driving table은 where이 있다면 필터링된 테이블로 join을 합니다. 선행테이블은 순차적으로 접근하고, 후행 테이블은 랜덤 액세스 데이터 수가 적을떄 유용 선행테이블은 where로 최대한 거르고, 행이 적은걸로 선택
for (...) // driving
for (...) // driven
🔎 빅오는 n2, 랜덤 액세스…?
merge join 두테이블을 정렬하고 join
hash join outer(right) table을 순회(scan)하여 join key를 해시키로 가지는 해시 테이블을 만듭니다. 후행 테이블은 만들어진 해시 테이블을, 같은 해시함수를 이용, 탐색하여 join하게 됩니다. 빅오는 n + n (hash테이블 탐색은 bigo 1), 일치 조건 join만 수행
https://hoon93.tistory.com/46 https://www.postgresql.org/docs/9.4/planner-optimizer.html
index scan, index onscan bitmap index sacn nested loop hash join mege join gather parallel
select * from pg_am show work_mem
btree balanced tree (balaced tree) logn 층 밸런스를 지킴 https://helloinyong.tistory.com/296 https://www.youtube.com/watch?v=NI9wYuVIYcA
hash index = 연산에만 쓰임
brin index Block Range INdex gin index
Trigger
• trigger란 테이블에 이벤트(INSERT/UPDATE/DELETE/TRUCATE)가 발생할때 자동으로 실행되는 함수입니다.
트리거 시점 BEFORE
AFTER
INSTEAD
테이블에 여러 트리거가 있으면 알파벳 순서로 실행됨
트리거 종류 Row Level Trigger
Statement Level Trigger
• Trigger 만들기
- function 만들기
CREATE FUNCTION trigger_function()
RETURNS TRIGGER
LANGUAGE PLPGSQL
AS $$
BEGIN
[trigger 로직]
END;
$$
- trigger - function 바인딩
CREATE TRIGGER trigger_name
{BEFORE|AFTER} {event}
ON table_name
[FOR [EACH] {ROW|STATEMENT}]
EXECUTE PROCEDURE trigger_function
Table Partition
table이 커지면, 조회 성능 등이 떨어지기에 table을 분리합니다. partition을 하면 기존 table은 master table이 되고 분리된 table은 partition table이 됩니다. 이때 master table의 data는 partition table로 옮겨집니다. master table 조회 시에는, partition table들의 data를 모두 보여줍니다. crud는 master table에 crud를 하면, partition table에 반영됩니다. 🔎 postgresql이 partition 기준에 따라, 데이터를 자동으로 partition table에 할당해주므로 select / update / delete / insert는 master table에 하는게 좋습니다. 🔎 where에 partition 기준 조건을 걸어, postgreql이 어떤 partition table에 작업할지 정의해주어야 합니다.
select * from [master table] -- 전체 partition table들의 data 보여줍니다.
select * from only [master table] -- master table의 data를 보여줍니다.
select * from [partition table] -- 해당 partition table의 data를 보여줍니다. (only와 결과가 같습니다.)
select * from only [partition table] -- 해당 partition table의 data를 보여줍니다.
master tabe\le
• partition type
partition 종류에는 range / list / hash 세 종류가 있습니다. - range 범위가 있는 column을 기준으로 table을 분리할 수 있습니다. 🔎 날짜별로 table을 분리할 때 좋습니다.
create table [master table 이름](
id int serial,
birth_date date not null,
) partition by range (birth_date)
create table [partion table 이름] partition of [master table 이름]
for values from [column 시작 값] to [column 끝 값];
- list 리스크가 있는 column을 기준으로 table을 분리할 수 있습니다. 🔎 코드별로 table을 분리할 때 좋습니다.
create table [master table 이름](
id int serial,
country_code varchar(2) not null,
) partition by list (country_code)
create table [partion table 이름] partition of [master table 이름]
for values in ([column 값 이름]);
- hash hash 값을 기준으로 table을 분리할 수 있습니다. 🔎 코드별로 table을 분리할 때 좋습니다.
create table [master table 이름](
id int serial,
) partition by hash (id)
create table [partion table 이름] partition of [master table 이름]
for values with (modulus [나눌수], remainder [나머지]);
- default table을 partition 한 뒤에는, 데이터가 partition 조건에 맞아야 삽입할 수 있습니다. 기준에 맞지 않는 데이터들은 default partition table에 삽입되게 됩니다.
create table [master table 이름](
id int serial,
) partition by hash (id)
create table [partion table 이름] partition of [master table 이름]
default;
Schema
Schema는 Database의 table, function 등의 집합입니다. schema를 통해 database를 정리할 수 있습니다. (Postgresql은 Database → Schema → Table의 집합관계를 가지고 있습니다.)
Security
6개의 lever instance level database level schema level table level column level row level
| Level | Security |
|---|---|
| Instance | Users, Roles, Database Creation, Login, Replication |
| Database | Connection, Creating, etc |
| Schema | Schema, etc |
| Table | Selecting, Inserting, Updating, etc |
| Column | Access |
| Row | Access |
instance 인스턴스에 있는 모든 DB를 제어합니다. supersuer, createdb, createrole, login, replication
role은 user와 같음
CREATE ROLE minho NOSUPERUSER NOCREATEDB NOCREATEROLE LOGIN PASSWORD 'qwerasdf';
GRANT [스키마 이름?] TO [USER/ROLE 이름];
• Database Level
create: 새로운 스키마 생성, connect: database 연결, temp/temporary: temporary table 생성
- connect database에 접근할 수 있는 권한을 role에게 줍니다.
GRANT CONNECT ON DATABASE [database 이름] TO [role 이름]
- create database에 schema를 만들 수 있는 권한을 role에게 줍니다.
GRANT CREATE ON DATABASE [database 이름] TO [role 이름]
• Schema Level
- create schema에 table, function 등을 만들 수 있는 권한을 role에게 줍니다.
GRANT CREATE ON SCHEMA [schema 이름] TO [role 이름]
- usage schema를 볼 수 있는 권한을 role에게 줍니다.
GRANT USAGE ON SCHEMA [schema 이름] TO [role 이름]
- revoke role에서 schema 권한을 없앱니다.
REVOKE ALL ON SCHEMA [schema 이름] FROM [role 이름?]
• Table Level
- select table에 select할 수 있는 권한을 role에게 줍니다.
GRANT SELECT ON TABLE [table 이름] TO [role 이름]
- insert table에 insert 수 있는 권한을 role에게 줍니다.
GRANT INSERT ON TABLE [table 이름] TO [role 이름]
- update table에 update할 수 있는 권한을 role에게 줍니다.
GRANT UPDATE ON TABLE [table 이름] TO [role 이름]
- DELETE table에 delete할 수 있는 권한을 role에게 줍니다.
GRANT DELETE ON TABLE [table 이름] TO [role 이름]
- TRUNCATE table에 truncate할 수 있는 권한을 role에게 줍니다.
GRANT TRUCATE ON TABLE [table 이름] TO [role 이름]
- TRIGGER table에 trigger할 수 있는 권한을 role에게 줍니다.
GRANT TRIGGER ON TABLE [table 이름] TO [role 이름]
- REFERENCES table에 외래키를 만들 수 있는 권한을 role에게 줍니다.
GRANT REFERENCES ON TABLE [table 이름] TO [role 이름]
- ALL 모든 table에 해당 db 권한을 role에게 줍니다.
GRANT [table 권한] ON ALL TABLE IN SCHEMA [schema 이름] TO [role 이름]
• Column Level
- select column에 select할 수 있는 권한을 role에게 줍니다.
GRANT SELECT ([column 이름]) ON [table 이름] TO [role 이름]
- insert column에 insert 수 있는 권한을 role에게 줍니다.
GRANT INSERT ([column 이름]) ON [table 이름] TO [role 이름]
- update column에 update할 수 있는 권한을 role에게 줍니다.
GRANT UPDATE ([column 이름]) ON [table 이름] TO [role 이름]
- references column에 외래키를 만들 수 있는 권한을 role에게 줍니다.
GRANT REFERENCES ([column 이름]) ON [table 이름] TO [role 이름]
• Row Level
• PGCRYPTO
Managing Table
• table 복사하기
- 데이터와 함께 복사하기
CREATE TABLE [새로운 table 이름] as (SELECT * FROM [원본 table 이름]);
- 데이터 없이 복사하기
CREATE TABLE [새로운 table 이름] as (SELECT * FROM [원본 table 이름]) WITH NO DATA;
create table trecord (like othertable including all); – 추가로 데이터도 넣어주기 insert into trecord (select * from othertable);
출처: https://mine-it-record.tistory.com/428 [나만의 기록들]
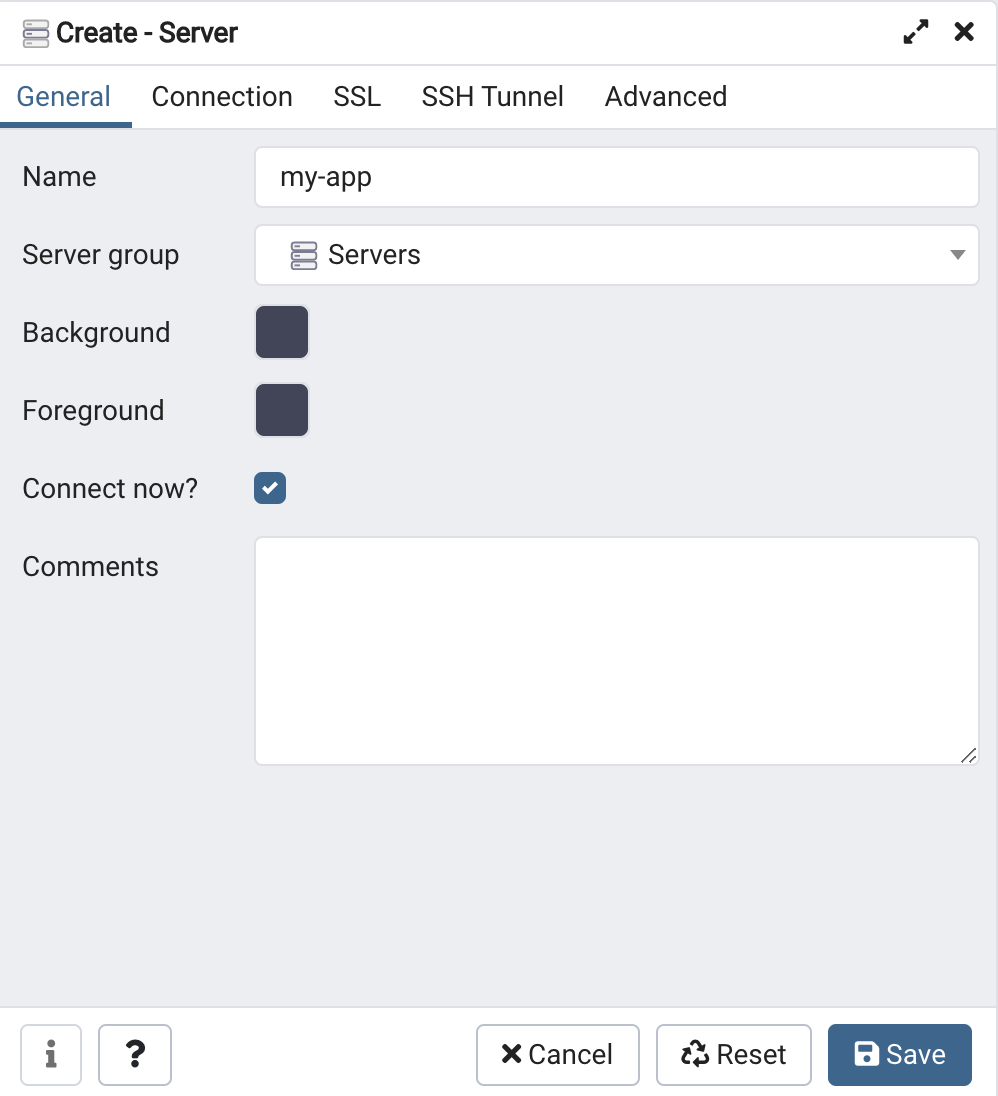
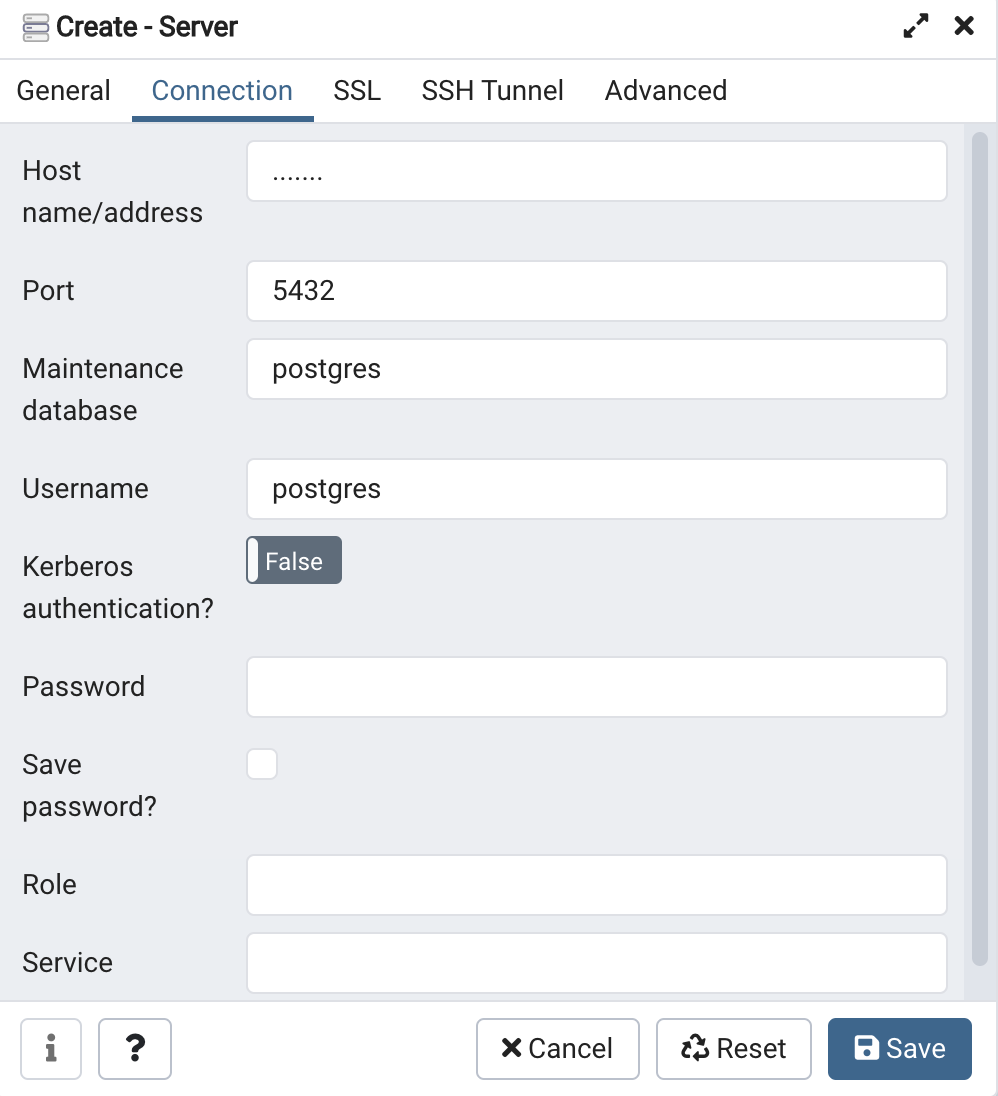
pgAdmin
• Server(Database) 만들기
• Google Cloud SQL
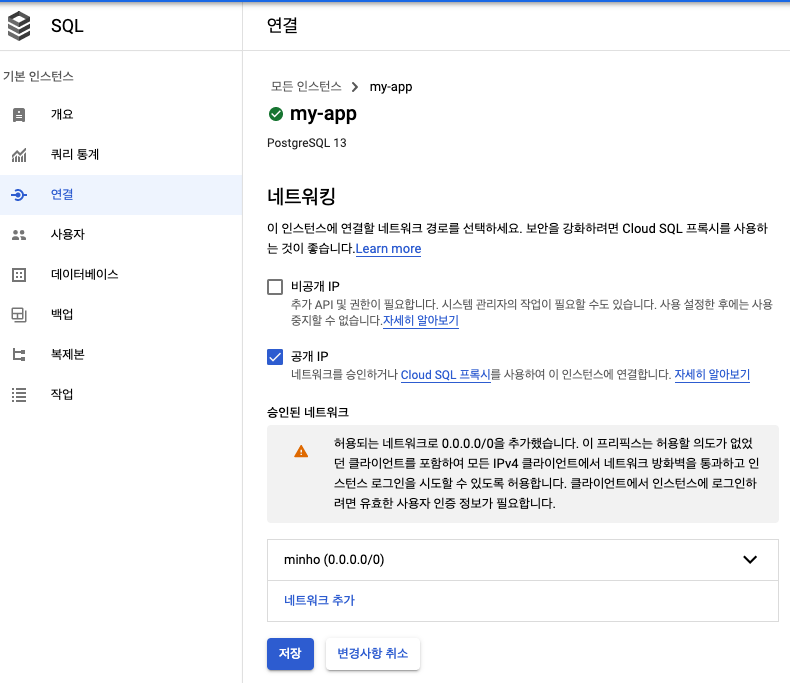
Google Cloud SQL에서 SQL Database를 저장할 수 있습니다. 클라우드를 만드는 법은 공식홈페이지에 기술되어 있습니다.
- PostgreSQL 인스턴스 만들기
- Cloud SQL 연결하기
Cheating Sheet
-- table 만들기
create table storages (
id bigint not null generated always as identity,
repo_id bigint not null,
name varchar not null,
created_at timestamp default now(),
is_edited boolean,
constraint storages_id_pkey primary key (id),
constraint storages_repo_id_fkey foreign key (repo_id) references repositories(id) on delete cascade
);
-- primary key 추가하기
alter table storages add constraint storages_name_pkey primary key (name);
-- primary key 삭제하기
alter table storages drop constraint storages_name_pkey;
-- foregin key 추가하기
alter table storages add constraint storages_repo_id_fkey foreign key (name) references repositories(id) on delete cascade;
-- foregin key 삭제하기
alter table storages drop constraint storages_repo_id_fkey;
-- not null constraint 추가하기
alter table storages alter column is_edited set not null;
-- not null constraint 삭제하기
alter table storages alter column is_edited drop not not null;
-- default 설정하기
alter table storages alter column is_edited set default true;
-- default 삭제하기
alter table storages alter column is_edited drop default;
-- unique 설정하기
alter table storages add constraint user_id_group_id_unique unique (user_id, group_id)
alter column is_edited set default true;
-- default 삭제하기
alter table storages alter column is_edited drop default;
-- table 이름 바꾸기
alter table storages raname to storages_b;
-- data type 바꾸기
-- column 추가하기
alter table storages add column mime_type varchar set default 'hello';
-- column 삭제하기
alter table storages drop column is_edited;
-- column 이름 바꾸기
-- 정렬하기
select * from storages order by created_at asc, id desc;
-- update 하기
update storages set is_edited = false where id = 3;
-- index 추가하기
-- 함수 만들기 (value 반환)
create or replace funcion fn_get_name(p_id bigint, p_is_edited boolean) returns varchar as
$$
select name from storages where id = p_id and is_edited = is_p_edited;
$$
language sql
-- 함수 만들기 (table 반환)
create or replace funcion fn_get_name(p_id bigint, p_is_edited boolean) returns varchar as
$$
select name from storages where id = p_id and is_edited = is_p_edited;
$$
language sql
-- for문 만들기
-- json 만들기
-- join vs subquery
-- import csv
-- export csv
-- transaction
-- trigger
-- unique 만들기
alter table storages add constraint unique_repo_id_name unique (repo_id, name)
-- duplicate table
create table new_storages as (select * from storages);
create table new_storages as (select * from storages) with no data;
-- 용량보기
select pg_size_pretty(pg_database_size([테이블 이름]));
select pg_size_pretty(pg_relation_size('storages')); -- data
select pg_size_pretty(pg_index_size('storages')); -- index
select pg_size_pretty(pg_total_relation_relation_size('storages')); -- data + index
참고 자료
• 유튜브 강의
• postgreSQL document
• postgreSQL tutorial
함수 https://www.tutorialspoint.com/postgresql/postgresql_useful_functions.htm
index
index
index
update / delete하면 기존거는 사용안하고, 새로운게 삽입되서 무거워짐…
https://wiki.postgresql.org/wiki/Main_Page
- Data Constraint Data의 Constraint를 정의할 수 있습니다.
- Data type Data Type을 정의할 수 있습니다.
postgres in 5432 error https://dev.to/balt1794/postgresql-port-5432-already-in-use-1pcf
https://d2.naver.com/helloworld/227936
dbpool https://brownbears.tistory.com/289
https://til.cybertec-postgresql.com/post/2019-09-02-Postgres-Constraint-Naming-Convention/
조인 방식 https://needjarvis.tistory.com/162
최신 데이터 가져오기 https://stackoverflow.com/questions/36701331/postgres-join-max-date https://www.geekytidbits.com/postgres-distinct-on/ https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=hsjnkkw&logNo=70179719126
role vs member https://www.postgresql.org/docs/11/role-membership.html
sql style guid https://www.sqlstyle.guide/#overview
unique https://www.postgresqltutorial.com/postgresql-unique-constraint/